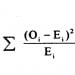 Chi: Bangumi 未来实验室 » 讨论
Chi: Bangumi 未来实验室 » 讨论
[Chi v0.2.1]同步率更新
#1 - 2015-2-8 20:59
Genius🌟小乖💯 (Enjoy your (real) life!)
我想接下来可能会有很多更新,为了不打扰大家就开了这个小组。
由于本人很忙,以后每次更新都只会在周末发布。而且也不一定能保证每个周末都会有更新。
本次更新的主要内容有:
调整了数学模型(但是计算同步率的思路没有改变。)这一调整的主要影响有:
很大程度上遏制了只有一两个收藏的用户进入前十名榜单;
较上一次相比,同步率有很大变化。
同时,增加了你在好友同步率中的排名。
显示用户名改为显示昵称。(对不起,我想这一改变可能会增加 Bangumi 服务器负担……)
可方便地获得适用于 Bangumi BBCode 的分享文本。
本次没有更新:
使得更多的活跃用户进入前十榜单;
数据仍然是2015年1月15日之前的数据。
最后,感谢 @Simon Chan @Doream @汐雨听潮 @Detao 对上一次算法的反馈。
感谢 @Donuts. @Venusxx 的建设性建议。
戳我
Enjoy.
由于本人很忙,以后每次更新都只会在周末发布。而且也不一定能保证每个周末都会有更新。
本次更新的主要内容有:
调整了数学模型(但是计算同步率的思路没有改变。)这一调整的主要影响有:
很大程度上遏制了只有一两个收藏的用户进入前十名榜单;
较上一次相比,同步率有很大变化。
同时,增加了你在好友同步率中的排名。
显示用户名改为显示昵称。(对不起,我想这一改变可能会增加 Bangumi 服务器负担……)
可方便地获得适用于 Bangumi BBCode 的分享文本。
本次没有更新:
使得更多的活跃用户进入前十榜单;
数据仍然是2015年1月15日之前的数据。
最后,感谢 @Simon Chan @Doream @汐雨听潮 @Detao 对上一次算法的反馈。
感谢 @Donuts. @Venusxx 的建设性建议。
戳我
Enjoy.
其实这个系统也能计算出全站与你同步率最低的十位用户,他们可能与你看的条目有重合,但是评价完全相反。这时候抛弃就能显示出价值了。
似乎是这里的表述偏离了重点。前一版本得出的同步率较高用户与我大概有5~10项共同喜好,并且这些用户的“想看”列表里存在相当数目我同样“想看”但尚未标记的番组。(所以我觉得这个体验相当好QuQ 虽然少但特别准
这个版本返回的第一名仅标记了一部作品,嗯,是共同抛弃。第二名的共同点一样。 = -
第三名向后很棒,尽管活跃用户不多,还是像上次一样找到了小小的惊喜。
感谢。
但是由于这个系统为了遏制少数收藏者进入榜单做了某些调整,使得性质 2 不符合。但是这不影响这个结论,因为证明过程没有用到性质 2.
结论就是:全站没有用户的前十名榜单中会有你。
是我理解的不对吗。。。
第一位,第七位还是弃了RRG,第八位第十位则是看过
第四位则是因为我弃了漆黑子弹
以上几位从bgm来看同步率为0
第九位同样弃RRG,12年就没来过了
第五位来一次性点了格子就没来过了
和点开的时光机页面不一样啊
那个sdascccc居然把qq密码写在介绍里....(跑题)
这都是什么鬼
算法真的是最简单不过而且拍脑袋就能想出来的算法:每个人评分在其平均分上面一减,喜欢什么不喜欢什么就都出来了,然后归一化求余弦距离,完了!
all models are wrong, but some are useful.
:)
很高兴lz提到假设一词,其实我的假设并不是“每个人加好友都看共同喜好”,而是“有些人加好友看共同喜好”(至少我是),和“按照别的标准加好友的人,他们的筛选标准和共同喜好相对独立”。这是一个更弱的假设,但这个假设合理的话,好友信息还是可以用的。
最后,好友信息的确不一定合适,我只是抛砖引玉一下,觉得这个小组可以在这方面多讨论一些,提出更多的可能性来。从个人经验来看,一个实际的ML project难的往往不是核心用什么算法,而正是做出有效(而不仅仅是正确)的假设,以及系统地建立评价机制(e.g. training/validation/test)。
顺便我是一个眼高手低的machine learning theorist(虽然我也自己写code),随口乱说,忽略实际的地方请随意鄙视。。
P.S. 刚看到这个
降维是个好方法,其实在 v0.1 里面我就用的降维,但是出来的结果令我百思不得其解,看来还是不能纸上谈兵啊。