2023-7-29 18:56 /
今日工作总结
1. 学习Docker打包镜像文件。考虑到作为产品而非单纯的算法开发,一条从前到后的比较完整的技术栈应该是必须的。目前,基于docker的打包-分发-部署比较受欢迎,部署方面还有一些不太熟悉的地方还需要请教同事。
2. 学习轻量化模型。学习了一批经典的的轻量化模型及其轻量化原理,如mobileNet v1, v2, v3和EffNet,分别使用了Depthwise Seperable Convolution和Spacial Sperable Convolution,对应了模型结构优化和矩阵分解两种模型压缩技术思路,在此之上有一众UNet模型的变体,可以尝试。
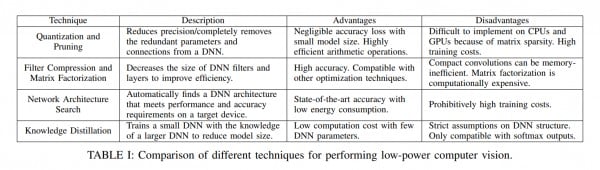
3. 了解模型压缩和加速的几大主要方法。有一点需要明确,模型压缩和模型加速都是当模型固定下来以后再做的一些改进,实际上模型结构层面的影响往往才是最大的那一环。因此应该先从网络类型的层面考虑,然后再考虑这些后面的问题。
参考论文:A Survey of Methods for Low-Power Deep Learning and Computer Vision(2020)
两篇不错的入门文章分享
一文看懂深度学习模型压缩和加速|知乎@扬易(@xieyangyi) 简枫 千瞳
https://zhuanlan.zhihu.com/p/138059904
腾讯邱东洋:深度模型推理加速的术与道|知乎@DataFunTalk
https://zhuanlan.zhihu.com/p/503613233?utm_id=0
4. 米茜动画教室直播,跟着米茜走了一遍日本动画制作流程,又获得了一些小知识。
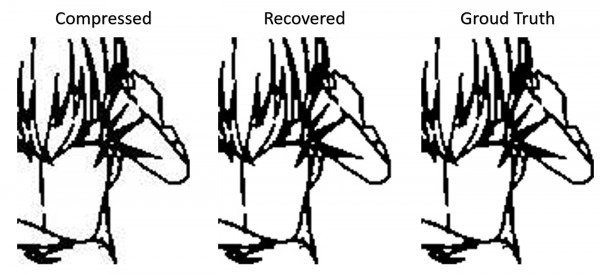
5. 低质量有损线稿的修复模型。基本效果就是把从视频或者其他什么地方截取的低质量黑白线稿给修复成高质量,不带噪点的二值线稿。对动画制作没有什么帮助,就是方便日后模型训练清洗数据用,这个项目很简单一个小时不到就做出来了,后面看看有没有什么具体的应用吧。
写在最后,一些无关紧要的想法:
在跟米茜直播,记录小知识的时候,我感到一丝不安。在最开始的狂热褪去之后,我逐渐意识到,必须时刻提醒自己,一个人应当保持表达欲望、不断分享自己的观点,但是又要清楚自己目前的能力边界在何处,不要因为虚荣、急功近利发表一些不负责的言论,成为所谓的“懂爷”。我应当清楚地认识,我目前所了解的关于动画的一切都只是道听途说,所有的AI技术都是浅表的皮毛,需要保持谦虚的而不卑微的姿态前进很长一段路。
1. 学习Docker打包镜像文件。考虑到作为产品而非单纯的算法开发,一条从前到后的比较完整的技术栈应该是必须的。目前,基于docker的打包-分发-部署比较受欢迎,部署方面还有一些不太熟悉的地方还需要请教同事。
2. 学习轻量化模型。学习了一批经典的的轻量化模型及其轻量化原理,如mobileNet v1, v2, v3和EffNet,分别使用了Depthwise Seperable Convolution和Spacial Sperable Convolution,对应了模型结构优化和矩阵分解两种模型压缩技术思路,在此之上有一众UNet模型的变体,可以尝试。
3. 了解模型压缩和加速的几大主要方法。有一点需要明确,模型压缩和模型加速都是当模型固定下来以后再做的一些改进,实际上模型结构层面的影响往往才是最大的那一环。因此应该先从网络类型的层面考虑,然后再考虑这些后面的问题。
参考论文:A Survey of Methods for Low-Power Deep Learning and Computer Vision(2020)

两篇不错的入门文章分享
一文看懂深度学习模型压缩和加速|知乎@扬易(@xieyangyi) 简枫 千瞳
https://zhuanlan.zhihu.com/p/138059904
腾讯邱东洋:深度模型推理加速的术与道|知乎@DataFunTalk
https://zhuanlan.zhihu.com/p/503613233?utm_id=0
4. 米茜动画教室直播,跟着米茜走了一遍日本动画制作流程,又获得了一些小知识。
5. 低质量有损线稿的修复模型。基本效果就是把从视频或者其他什么地方截取的低质量黑白线稿给修复成高质量,不带噪点的二值线稿。对动画制作没有什么帮助,就是方便日后模型训练清洗数据用,这个项目很简单一个小时不到就做出来了,后面看看有没有什么具体的应用吧。

写在最后,一些无关紧要的想法:
在跟米茜直播,记录小知识的时候,我感到一丝不安。在最开始的狂热褪去之后,我逐渐意识到,必须时刻提醒自己,一个人应当保持表达欲望、不断分享自己的观点,但是又要清楚自己目前的能力边界在何处,不要因为虚荣、急功近利发表一些不负责的言论,成为所谓的“懂爷”。我应当清楚地认识,我目前所了解的关于动画的一切都只是道听途说,所有的AI技术都是浅表的皮毛,需要保持谦虚的而不卑微的姿态前进很长一段路。