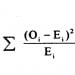 Chi: Bangumi 未来实验室 » 讨论
Chi: Bangumi 未来实验室 » 讨论
[同步率改 v0.3]分类同步率、喜好反馈与活跃度控制
#1 - 2015-3-8 09:39
Genius🌟小乖💯 (Enjoy your (real) life!)
Dear BGMers:
我诚邀各位前往同步率改感受一下 Chi 的最新动态。正如标题所暗示的,本次更新除了算法更新之外,还为同步率增加了许多激动人心的新功能。
1. 分类同步率。现在各位可以看到自己在某一类别中的同步率。我认为,这样的改进能使得那些在独特领域有专长的 BGMer 更深入地了解 BGM 与自己持有相近兴趣的人的分布情况。
2. 喜好反馈。现在在查看你与某一位 BGMer 的时候,你可能会发现在下方写了你与他/她在某几部作品上持有相同看法。如果你和他/她的同步率降到 50% 以下,反馈可能会给出你与他/她在某几部作品上持有相反看法。@若卡 你点的菜!
3. 活跃度控制。现在在查看前十位同步率用户榜单的时候,可以加入活跃度控制选项。
另外,本次更新对于算法的详细过程,我已经 po 到了这里。几位业界人士@Kane @Glenn 如果有兴趣可以来评议一下
Cheers
Nya
我诚邀各位前往同步率改感受一下 Chi 的最新动态。正如标题所暗示的,本次更新除了算法更新之外,还为同步率增加了许多激动人心的新功能。
1. 分类同步率。现在各位可以看到自己在某一类别中的同步率。我认为,这样的改进能使得那些在独特领域有专长的 BGMer 更深入地了解 BGM 与自己持有相近兴趣的人的分布情况。
2. 喜好反馈。现在在查看你与某一位 BGMer 的时候,你可能会发现在下方写了你与他/她在某几部作品上持有相同看法。如果你和他/她的同步率降到 50% 以下,反馈可能会给出你与他/她在某几部作品上持有相反看法。@若卡 你点的菜!
3. 活跃度控制。现在在查看前十位同步率用户榜单的时候,可以加入活跃度控制选项。
另外,本次更新对于算法的详细过程,我已经 po 到了这里。几位业界人士@Kane @Glenn 如果有兴趣可以来评议一下
Cheers
Nya
你们在魔法少女小圆、心理测量者和死亡笔记等作品上持有相反评价。
怎么那么低
4. RMSE 里面计算的都是已经打分的记录与预测值的差距,没有打分的不计算。你好像认为我会给用户所有的未打分条目预测分值?我只给用户已经收藏但未打分的条目预测分值。而且这个罚项正是我想要的目的:用户已收藏未打分的估计值对同步率影响力不能太大。
3. 哦,对,是这样的。
2. U 和 V 都是 SVD,Bu(Bias of user)是用户所有打分条目中处于某一状态(如在看)平均值减去用户全部评分平均值,Bi(Bias of item)是已经减去用户平均值的作品评分基础上,某一作品处于某种收藏状态的平均值减去该作品平均评分值。
1. cross-validation 好啊,但是怎么量化表现“表达能力和泛化能力的平衡”呢?做 cross-validation 计算量超大的。哦,那个 Q 在动画类里面取了 800,我真的不知道怎么取。动画类 utility matrix 是一个40000 x 8000 的矩阵,是按照 SVD 之后的 singular value 占 trace 的比重取的吗?
Q的选取除了CV还真没什么好的办法。至于如何有效地做CV,你现在好像是把条目分成了training/validation/test。其实可以直接在R里randomly挖掉一些孔(用户打分的条目)当作validation/test。。不知道这样会不会让CV快一点?
1、2:Bangumi 的条目是否评分,与条目收藏状态是互相独立的。这个 bias 的目的就是要利用条目所处状态的信息,U 和 V 都不会包含状态信息。所以 Bu 是一个用户数 x 状态数(5)的矩阵。
3. 哦,我没有估计所有未评分条目,我只是估计了用户已收藏但未评分的条目的分值。
4. Oh yes you are right,不过我想多接触一些算法,用不同的模型去解决问题比如说RBM之类的
因为为了防止具有很少收藏的人进入前十榜单,在计算的时候做了某些 trick。其实这是不科学的。但是如果我按照真实的同步率展示,BGMer 们又要说我不科学。在下一个玩具设计出来之前,这个 feature 不会有所改变。