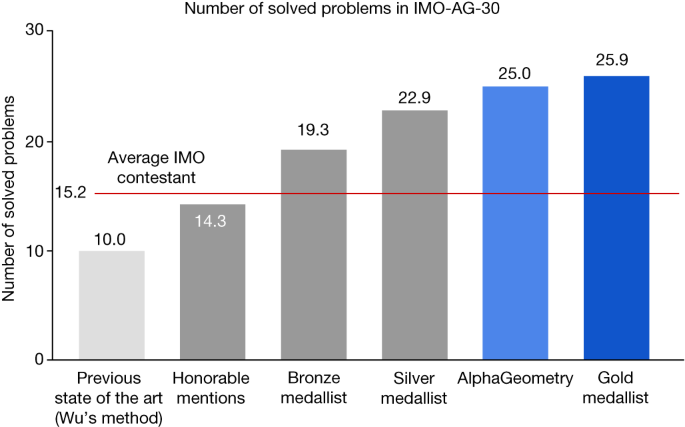
Fig. 2: AlphaGeometry advances the current state of geometry theorem prover from below human level to near gold-medallist level.
圖2:AlphaGeometry 將幾何定理證明器的當前狀態從低於人類水平提升到接近金牌得主水平。
有类似 Coq 的形式化验证工具参与是非常合理的,它可以保证当 AI 一旦给出证明,这个证明就一定是正确的。对于仅由人工神经网络构成的 AI 给出的数学证明,首先这证明不一定对;然后如果是对的,也需要进行额外的检查才能确保其正确性
人类使用形式化验证工具来做数学证明的原理其实和 AlphaGeometry 是类似的。形式化验证工具提供的自动证明是机械的暴力搜索,一般只用来解决比较显然的问题;对于复杂一些的问题,也是需要设立若干个中间引理,当一个引理足够显然时就可以让工具自动证明。设立哪些引理的证明思路是关键,这本来需要依靠人的直觉,而现在看起来 AI 也可以建立类似的直觉

人类使用形式化验证工具来做数学证明的原理其实和 AlphaGeometry 是类似的。形式化验证工具提供的自动证明是机械的暴力搜索,一般只用来解决比较显然的问题;对于复杂一些的问题,也是需要设立若干个中间引理,当一个引理足够显然时就可以让工具自动证明。设立哪些引理的证明思路是关键,这本来需要依靠人的直觉,而现在看起来 AI 也可以建立类似的直觉
我没看他们的 blog,不知道他们用的符号逻辑程序的表达能力怎么样。但如果他们用 Coq 的话,我目前不知道有哪个数学分支是 Coq 无法表达的