#1 - 2022-3-2 03:57
NekoNull
联动 bangumi有一天会关闭么? 和 Sai 老板的指引,使用 Bangumi API 写了一些 Python 脚本,一个导出数据到 JSON,一个把 JSON 转换成稍微可以读的 HTML。
项目地址:https://github.com/jerrylususu/bangumi-takeout-py
2023/8/2 更新:现已支持 Github Actions,具体使用请参考 README
2022/12/1 更新:备份工具使用量过大,造成 Bangumi 全站缓慢,被 Sai 吐槽了。已经减缓请求频率,备份耗时可能增加。
2022/6/22 更新:欢迎尝试实验性项目 Bangumi Takeout More,现已支持小组讨论、日志、目录导出。
2022/5/24 更新:现已支持增量导出和导出至 CSV。
2022/5/10 更新:因为上游 API (Bangumi API) 的收藏接口出现了一个 Bug,2022/3/6 之后导出的数据可能存在评论错乱问题(指多个条目下有重复的「个人评价」)。这个 Bug 现在已经被修复。如果发现自己的导出记录中存在此类问题,您可能需要重新导出一次。
2022/3/3 更新:🎉现已支持在 Colab 上运行,无需任何本地部署!点此尝试:
结果大概长这样(示例链接):
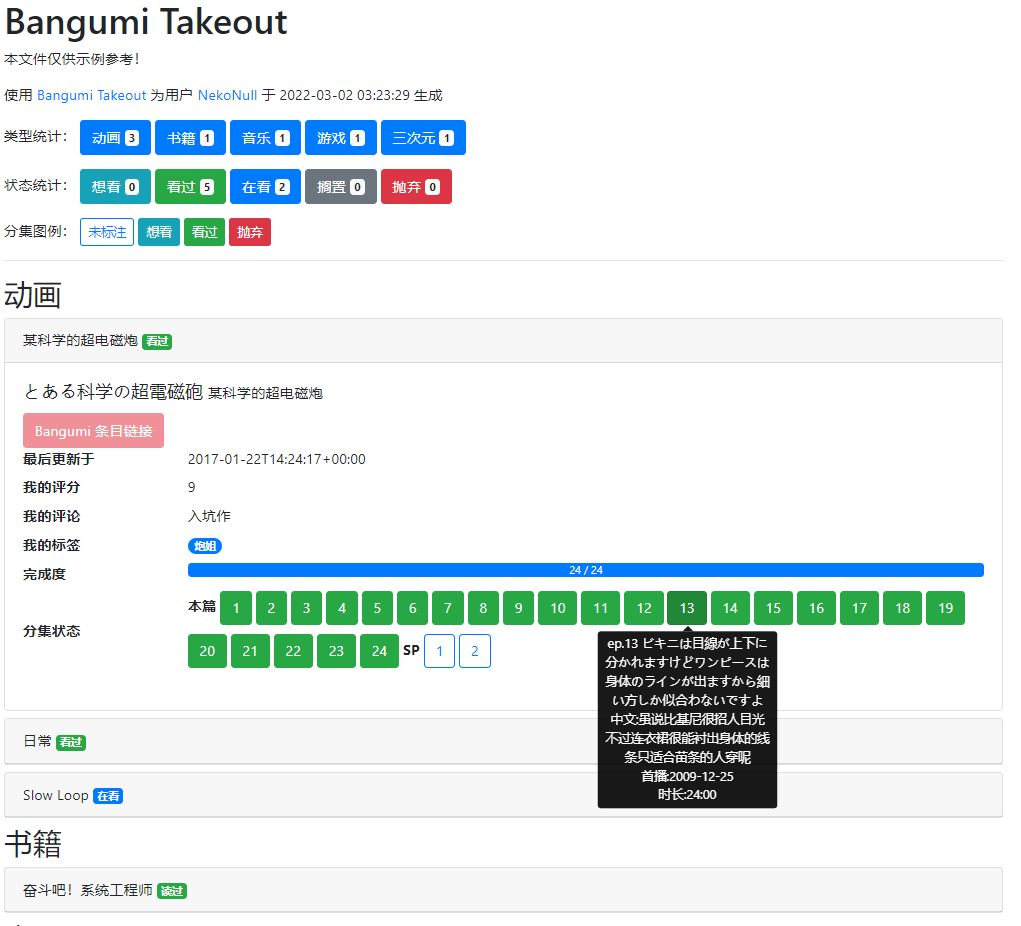
欢迎各路大触 PR !也欢迎各位用自己的账户测试,因为我自己点的格子还挺少的(示例文件做了裁剪,自己实际上不到 100 个),所以肯定有部分条目是有问题的,只是我现在发现不了
项目地址:https://github.com/jerrylususu/bangumi-takeout-py
2023/8/2 更新:现已支持 Github Actions,具体使用请参考 README
2022/12/1 更新:备份工具使用量过大,造成 Bangumi 全站缓慢,被 Sai 吐槽了。已经减缓请求频率,备份耗时可能增加。
2022/6/22 更新:欢迎尝试实验性项目 Bangumi Takeout More,现已支持小组讨论、日志、目录导出。
2022/5/24 更新:现已支持增量导出和导出至 CSV。
2022/5/10 更新:因为上游 API (Bangumi API) 的收藏接口出现了一个 Bug,2022/3/6 之后导出的数据可能存在评论错乱问题(指多个条目下有重复的「个人评价」)。这个 Bug 现在已经被修复。如果发现自己的导出记录中存在此类问题,您可能需要重新导出一次。
2022/3/3 更新:🎉现已支持在 Colab 上运行,无需任何本地部署!点此尝试:
结果大概长这样(示例链接):
欢迎各路大触 PR !也欢迎各位用自己的账户测试,因为我自己点的格子还挺少的(示例文件做了裁剪,自己实际上不到 100 个),所以肯定有部分条目是有问题的,只是我现在发现不了
没有做一次性的导出和导入所以的动画、图书和游戏。
另外你点入任何用户收藏页面,都可以导出ta的收藏。
这样就不怕bangumi突然关站啦
2. 我前端技能树点的不是很多,当前选择完全输出至 HTML 只是因为实现起来比较简单。另一种方式可能是实现一个类似于「数据浏览器」的前端网页,选择导出的 json 文件之后动态加载。这部分可以通过写其他的 generator 实现,其他开发者也可以自己实现。(另:太长指的是多少?千级?)
3. 如果指的是从其它网站导入数据,会存在需要把数据关联到 Bangumi 对应条目的问题。而如果指的是重新导入此前用本工具导出的数据,我暂时想不到什么场景下会需要这一功能,欢迎回复讨论。
2. 一个ACG长老,完全有可能收集数以万计的条目。
3. 同步用户数据,当你在旧账户和新账户中分别有相当数量的条目,想要合并时,这个功能就会发挥作用。
3. 对于这一点,理论上可以在生成 HTML 的时候,从多个 takeout.json 中获取数据,相当于本地合并。如果直接修改 Bangumi 数据,感觉有可能触发 API 速率限制。
#19 的用户脚本是以 CSV 格式导出的,后来又更新为 .xlsx 格式,所以可以很容易地在电子表格软件中使用。
它似乎完全满足了我对用户数据迁移的需要。它输出的数据相对较少,而且不能记录你看过多少集。我认为可以用一种方法来记录数据,创建一个新的字段,数据格式为 "EP 001~009, 011~013; SP 001~005"。
我没有学过编程,不能顺利地将 json 格式导入电子表格。我认为 CSV 格式已经足够用于迁移用户数据,而且在电子表格中排列、汇总比HTML格式更方便。
我认为条目的详细信息(例如每一话的标题、歌曲的曲目列表等)应该以另一种方式存储,导出仅仅记录需要的数据。
https://github.com/jerrylususu/bangumi-takeout-py/issues/6
当然,有些人可能希望能够导出他们自己的短评论(吐槽)、长评论、Tags 等。有些人希望在 ep 下留下自己与他人的讨论。
我认为只要是用户自己写的,就可能是有意义的。但要导出所有的讨论应该是很困难的,如果有太多的收藏,数据会变得很大。
至于可能触发API限制的导入,我认为可以 "愚公移山",每天保存100条信息,10天保存1000条信息。
如果继续使用现在的完成度表达方法,感觉可以把“完成的集数”和“总集数”分成两列。“完成度(百分比)”可以从电子表格中计算出来,可以考虑删除这一栏。
关于分集的表现形式,我在上面举了一个例子:"EP 001~009, 011~013; SP 001~005"。意思是我已经完成了正片的第 1~9 话,11~13 话,而第 10 话未看。另外完成了 SP 1~5 话。我所想到的就是这种表示方法,供参考。
https://github.com/jerrylususu/bangumi-takeout-py/issues/11
不过目前只是简单建了个 yml,代码层面没有做并行化。其实大部分数据从 archive 取的话,串行请求也够了,最耗时的也就是获取每个收藏的进度。我自己试了下,~140个收藏12分钟也跑完了,考虑到 Github Actions 有6个小时运行时间限制,一般情况下应该够用了。
使用体验补充:总收藏条目超过3k的用户请不要使用github action,大概率会超时。