#1 - 2017-12-25 15:25
君寻 (已淡出bgm38)
样本数约为 0~100
平均值约为 40
简单Multiple (v*r/C)
严重缺点是没有区分低分与高分的众数效应,如3分 100人评分与 10分 30人评分算下来是等价的,这种算法显然不可用。
贝叶斯平均
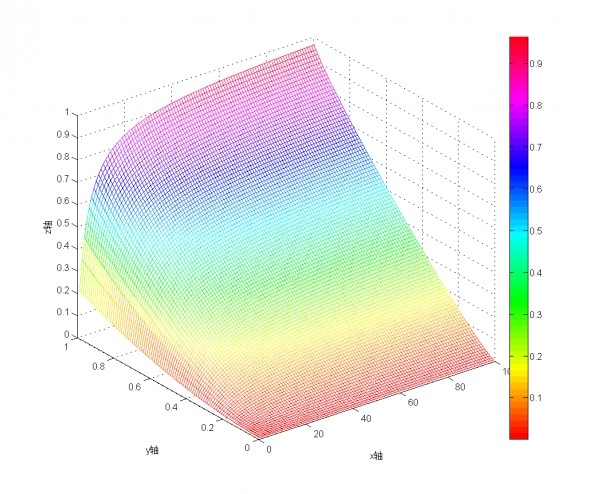
典型的就是IMDB排名算法((v/(v+m))*R + (m/(v+m))*C))
缺点是在R=C时没有区分度,如果平均分较高,整个区间会比较窄
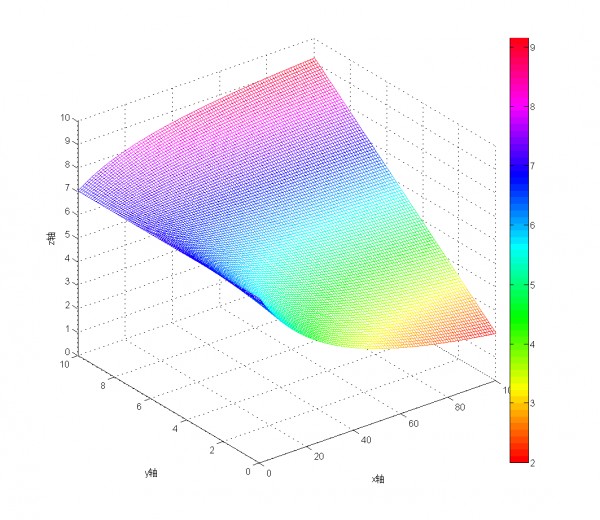
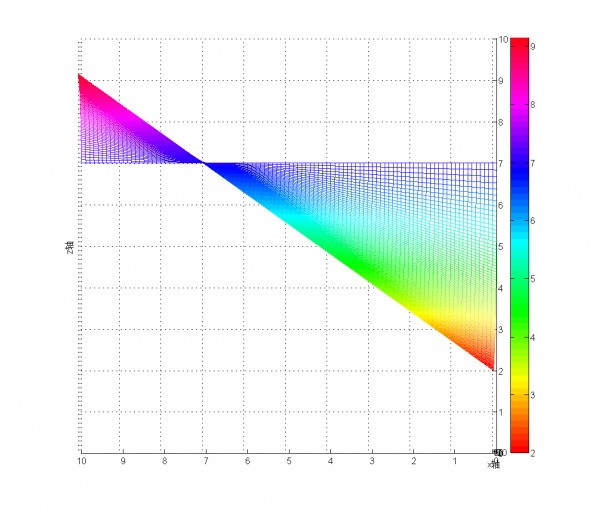
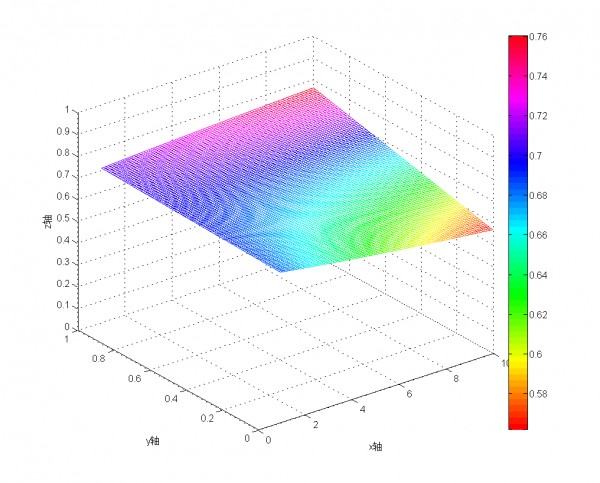
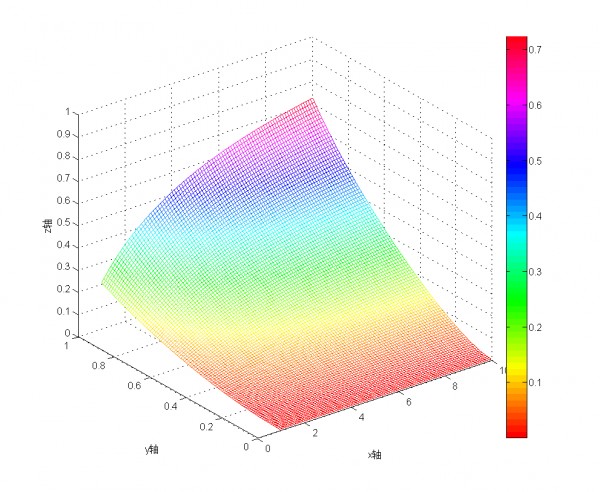
Wilson区间法
基本思想:
第一步,计算每个项目的"好评率"(这里可以将评分化为(0-1)区间)
第二步,计算每个"好评率"的置信区间(以95%的概率)
第三步,根据置信区间的下限值,进行排名。值越大,排名就越高
Edwin Bidwell Wilson 修正公式:
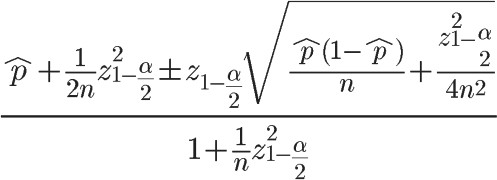
p 表示样本的"好评率",n表示样本的大小,z(1-α/2)表示对应某个置信水平α的z统计量,一般情况下,在95%的置信水平下,z统计量的值为1.96。
这个算法虽然保证了排名的可信性,但也带来了另一个问题:排行榜前列总是那些票数最多的项目,新项目或者冷门的项目,很难有出头机会,排名可能会长期靠后。
平均值约为 40
严重缺点是没有区分低分与高分的众数效应,如3分 100人评分与 10分 30人评分算下来是等价的,这种算法显然不可用。
典型的就是IMDB排名算法((v/(v+m))*R + (m/(v+m))*C))
缺点是在R=C时没有区分度,如果平均分较高,整个区间会比较窄



基本思想:
第一步,计算每个项目的"好评率"(这里可以将评分化为(0-1)区间)
第二步,计算每个"好评率"的置信区间(以95%的概率)
第三步,根据置信区间的下限值,进行排名。值越大,排名就越高
Edwin Bidwell Wilson 修正公式:
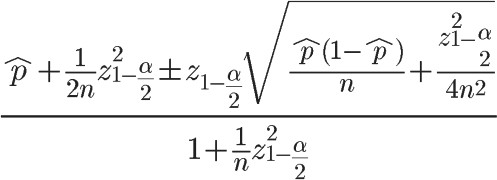
p 表示样本的"好评率",n表示样本的大小,z(1-α/2)表示对应某个置信水平α的z统计量,一般情况下,在95%的置信水平下,z统计量的值为1.96。
这个算法虽然保证了排名的可信性,但也带来了另一个问题:排行榜前列总是那些票数最多的项目,新项目或者冷门的项目,很难有出头机会,排名可能会长期靠后。


所以只要有机制存在,就有刷的可能。完全只是成本和收益的考虑而已所以卖握手券才是终极投票手段啊